TLDR: As of 24/01/2023, 12PM AEDT, the default view of 100 Warm Tunas will display results with an ML model applied to them, in their new order. Results which have changed ranks due to the adjustment will be marked with text "✨ ML Model Applied", along with the original rank:
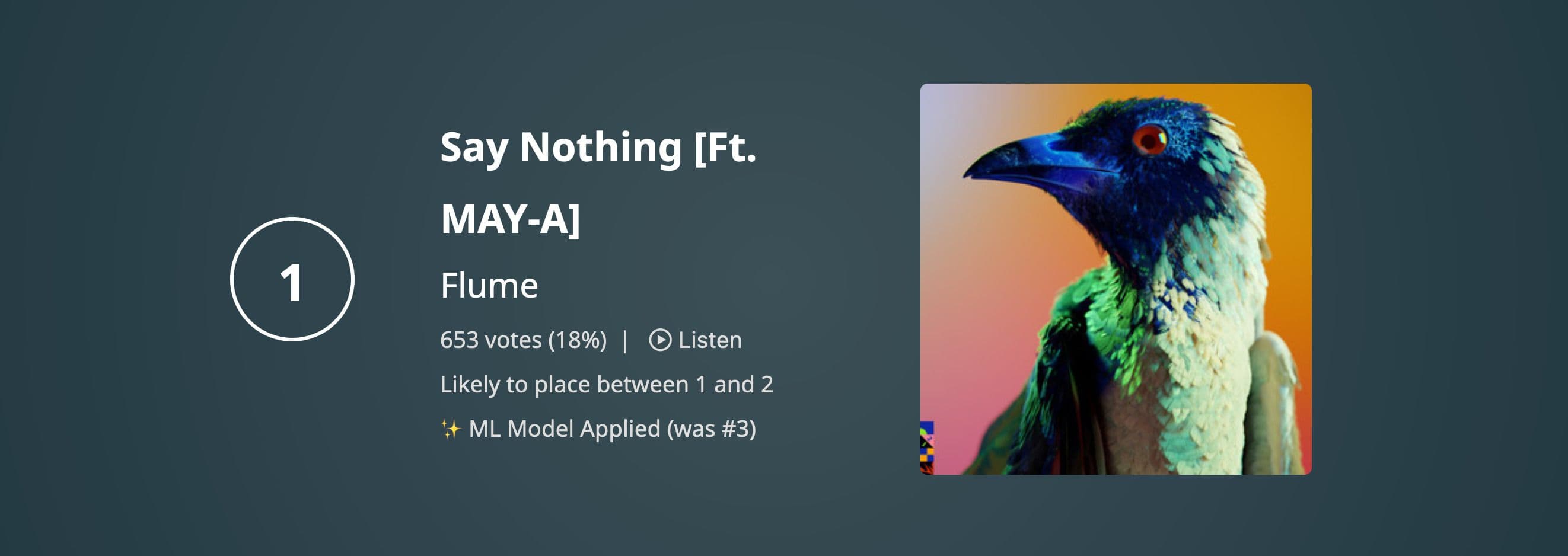
Example of a result where ranks have changed due to adjustment
The vote counts displayed on the prediction will continue to be the true number of votes collected. You can opt out of ML applied ordering by using the controls overlay.
We hope you enjoy these improvements to 100 Warm Tunas. If you want to show your appreciation for the work that I do, you can help contribute to the project by buying me a coffee ☕️.
A Deep Dive into 100 Warm Tunas ML Model
100 Warm Tunas collects voting slips posted by people to various social networks, and tallies the votes for each song to produce an overall prediction.
This method of collecting data has a potential downside - selection bias. Selection bias occurs when the sample of data that is collected is not representative of the entire population. In this case, the sample of voting slips that is collected only represents a small percentage of the total number of votes, which means that the results may not be representative of the entire population of voters
Over the last 6 years, we've seen a handful of patterns emerge in the predictions which 100 Warm Tunas provides. Many of our users also are aware of this. For example, 100 Warm Tunas will frequently rank Australian rock tracks significantly higher than they place on Hottest 100 day.
Having 6 years of historical data puts us in a unique position. We have information about how the algorithm predicted songs and can compare this to how the song actually placed (error). This information can be used to train an ML model to predict error in new, unseen datasets and adjust for biases that may exist in the data that we collect.
So first, you might be wondering what ML is? Machine learning (ML) is a method of teaching computers to learn from data, without being explicitly programmed. It is a type of artificial intelligence that allows computers to automatically improve their performance with experience. The algorithm is presented with a dataset, which includes input data and the corresponding correct output. The computer uses this dataset to learn mappings and patterns from inputs (features) to outputs (labels). Once the model has learned this mapping, it can be used to make predictions on new, unseen data.
For 100 Warm Tunas, we can train a model to attempt to predict the error based on previous countdown results. This is considered a regression problem (the aim is to predict the output of a continuous value). Contrast this with a classification problem, where the aim is to select a class from a list of classes.
For every countdown, we have the following data:
| song | artists | rank_predicted | vote_count | rank_actual | rank_error |
|---|---|---|---|---|---|
| Elephant [triple j Like A Version 2021] | The Wiggles | 1 | 541 | 1 | 0 |
| the angel of 8th ave. | Gang of Youths | 2 | 478 | 6 | 4 |
| Stay | The Kid LAROI, Justin Bieber | 3 | 352 | 2 | -1 |
| good 4 u | Olivia Rodrigo | 4 | 289 | 4 | 0 |
| Kiss Me More [Ft. SZA] | Doja Cat, SZA | 5 | 269 | 7 | 2 |
| On My Knees | RÜFÜS DU SOL | 6 | 269 | 9 | 3 |
| Lots Of Nothing | Spacey Jane | 7 | 265 | 3 | -4 |
| Hertz | Amyl and The Sniffers | 8 | 256 | 28 | 20 |
| Happier Than Ever | Billie Eilish | 9 | 255 | 5 | -4 |
| Sunscreen | Ball Park Music | 10 | 235 | 21 | 11 |
Using this data, we can then extrapolate the number of votes required for a given song to have been predicted in the correct position:
| song | rank_predicted | rank_actual | vote_count | vote_count_for_result | vote_count_error |
|---|---|---|---|---|---|
| Elephant [triple j Like A Version 2021] | 1 | 1 | 541 | 541 | 0 |
| the angel of 8th ave. | 2 | 6 | 478 | 269 | -209 |
| Stay | 3 | 2 | 352 | 478 | 126 |
| good 4 u | 4 | 4 | 289 | 289 | 0 |
| Kiss Me More [Ft. SZA] | 5 | 7 | 269 | 265 | -4 |
| On My Knees | 6 | 9 | 269 | 255 | -14 |
| Lots Of Nothing | 7 | 3 | 265 | 352 | 87 |
| Hertz | 8 | 28 | 256 | 145 | -111 |
| Happier Than Ever | 9 | 5 | 255 | 269 | 14 |
| Sunscreen | 10 | 21 | 235 | 162 | -73 |
However, in this instance, vote_count_error is absolute. We must normalise this to be relative to
the vote count in order for neural network to correctly identify patterns.
| song | rank_predicted | rank_actual | vote_count | vote_count_for_result | vote_count_error |
|---|---|---|---|---|---|
| Elephant [triple j Like A Version 2021] | 1 | 1 | 541 | 541 | 0 |
| the angel of 8th ave. | 2 | 6 | 478 | 269 | -0.437238 |
| Stay | 3 | 2 | 352 | 478 | 0.357955 |
| good 4 u | 4 | 4 | 289 | 289 | 0 |
| Kiss Me More [Ft. SZA] | 5 | 7 | 269 | 265 | -0.0148699 |
| On My Knees | 6 | 9 | 269 | 255 | -0.0520446 |
| Lots Of Nothing | 7 | 3 | 265 | 352 | 0.328302 |
| Hertz | 8 | 28 | 256 | 145 | -0.433594 |
| Happier Than Ever | 9 | 5 | 255 | 269 | 0.054902 |
| Sunscreen | 10 | 21 | 235 | 162 | -0.310638 |
In order to actually build a model, we must also have some inputs (features). We've used some of the following features to train the model:
- Artist (To account for patterns of artist bias found in the sample)
- Artist Genre (To account for patterns of genre bias found in the sample)
- Duration
- Tempo
- Predicted rank
- Various Spotify Attributes
| song | artists | genres | duration_ms | tempo | danceability |
|---|---|---|---|---|---|
| Elephant [triple j Like A Version 2021] | The Wiggles | australian children's music, children's music | 202293 | 127.887 | 0.513 |
| the angel of 8th ave. | Gang of Youths | australian indie, modern rock | 238653 | 89.551 | 0.463 |
| Stay | The Kid LAROI, Justin Bieber | australian hip hop, pop, rap | 141805 | 169.928 | 0.591 |
| good 4 u | Olivia Rodrigo | pop | 178146 | 166.928 | 0.563 |
| Kiss Me More [Ft. SZA] | Doja Cat, SZA | dance pop, pop | 208866 | 110.968 | 0.762 |
| On My Knees | RÜFÜS DU SOL | australian electropop, edm, indietronica | 261001 | 120.044 | 0.683 |
| Lots Of Nothing | Spacey Jane | australian indie rock, fremantle indie, perth indie | 196533 | 139.985 | 0.58 |
| Hertz | Amyl and The Sniffers | australian garage punk | 153800 | 184.657 | 0.329 |
| Happier Than Ever | Billie Eilish | art pop, electropop, pop | 298899 | 81.055 | 0.332 |
| Sunscreen | Ball Park Music | australian indie, australian pop, brisbane indie | 250116 | 151.155 | 0.348 |
With these inputs (features), and known good outputs (labels), we can now train a model. Once the model is trained, it can then be tested on a validation set, which was subtracted from the dataset prior to training in order to test its performance.
The following diagram demonstrates how closely the model is able to predict the vote count error for the previously extracted validation set. The closer to the blue line, the more accurate the predicted adjustment is:
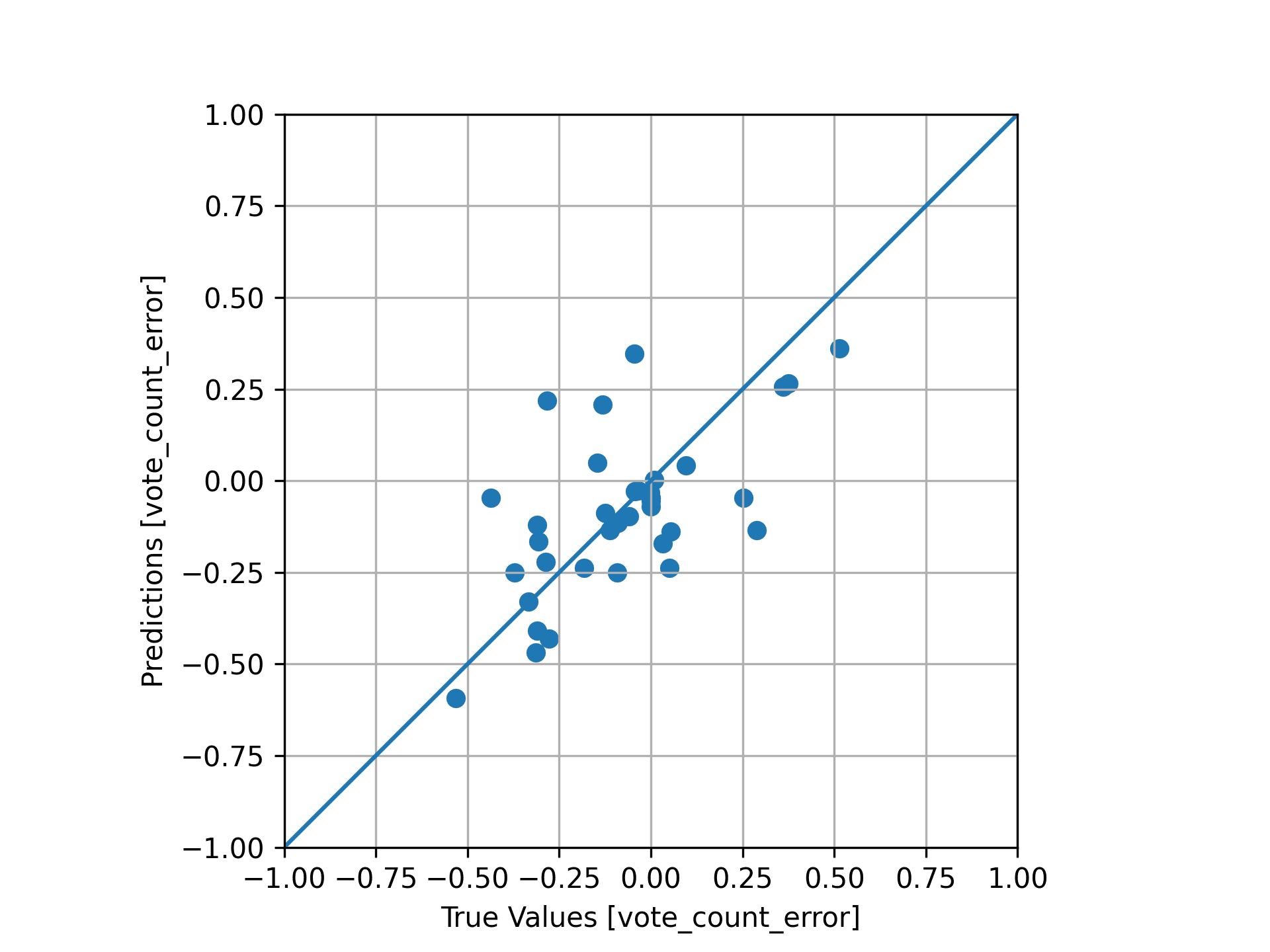
Validation set fit
We can also take a look generally at how all of the training data looks when plotted:
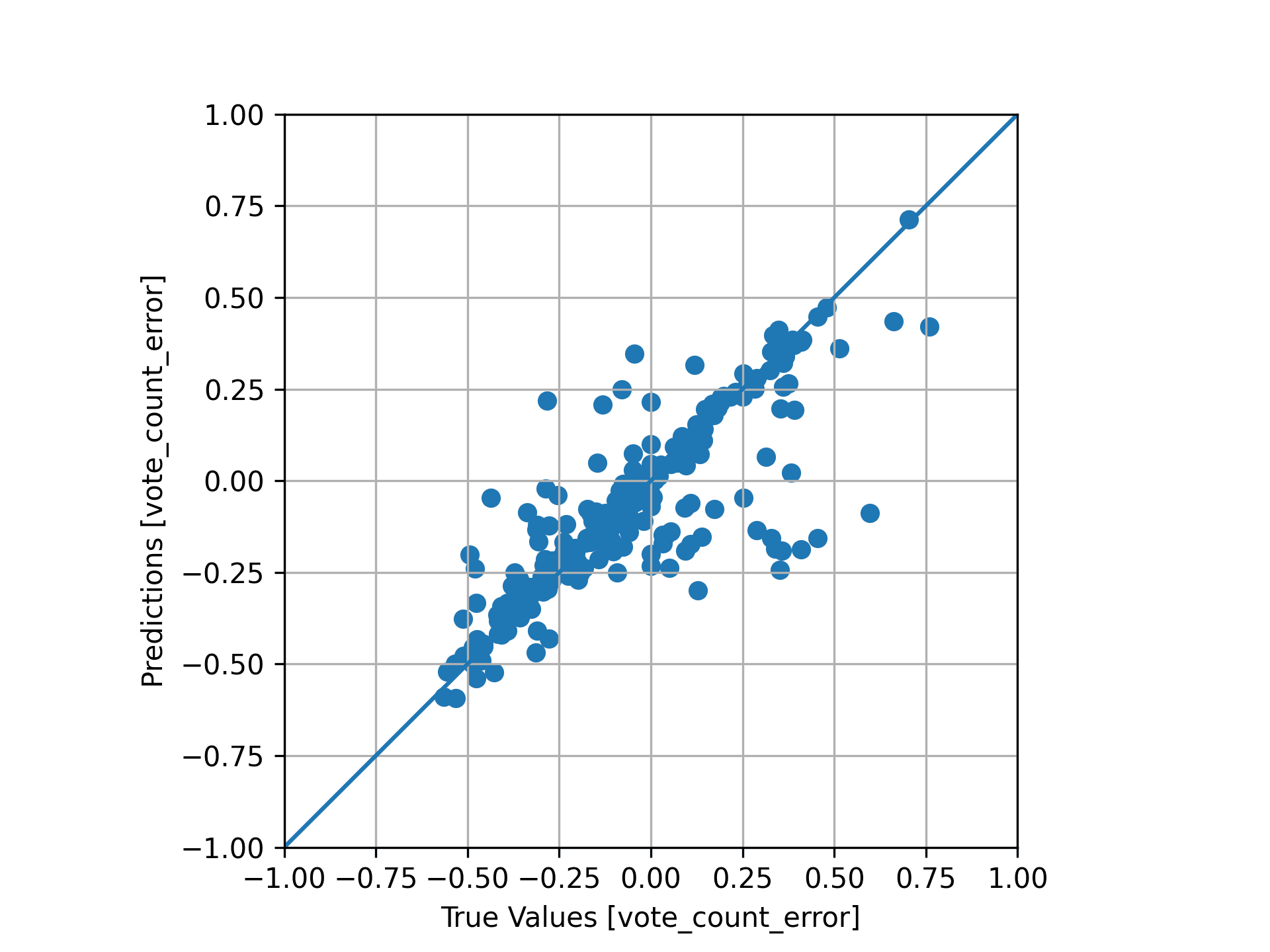
Training data fit
Finally, as one last test, we re-train the model, except this time reserving the 2021 countdown data as our validation set:
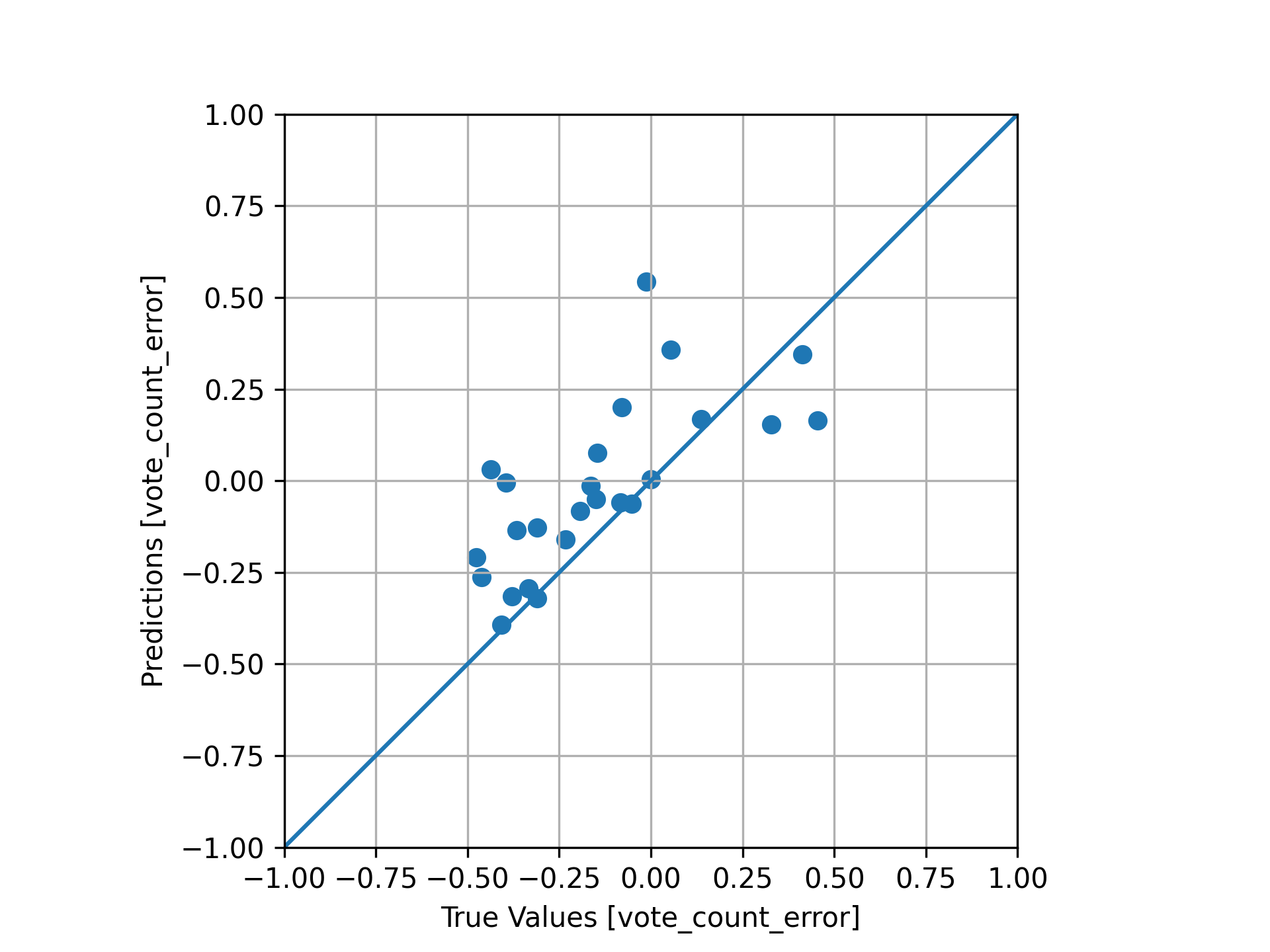
Unseen 2021 data fit
Armed with a trained model, we can then apply it to our unseen data (2022's predictions) which we have no known good/expected output (vote_count_error):
| song | rank_predicted | vote_count | vote_count_error_pred |
|---|---|---|---|
| in the wake of your leave | 1 | 803 | |
| Stars In My Eyes | 2 | 727 | |
| Say Nothing [Ft. MAY-A] | 3 | 653 | |
| Hardlight | 4 | 652 | |
| New Gold [Ft. Tame Impala/Bootie Brown] | 5 | 555 | |
| Sitting Up | 6 | 475 | |
| Camp Dog | 7 | 444 | |
| Girl Sports | 8 | 444 | |
| This Is Why | 9 | 434 | |
| Delilah (pull me out of this) | 10 | 432 | |
| Let's Go | 11 | 426 | |
| B.O.T.A. (Baddest Of Them All) | 12 | 419 | |
| Get Inspired | 13 | 399 | |
| Bad Habit | 14 | 333 | |
| Backseat Of My Mind | 15 | 270 | |
| Glimpse of Us | 16 | 263 | |
| It's Been A Long Day | 17 | 257 | |
| God Is A Freak | 18 | 251 | |
| sTraNgeRs | 19 | 244 | |
| About Damn Time | 20 | 237 | |
| Stranger Days | 21 | 233 | |
| Shooting Stars [Ft. Toro y Moi] [LaV 2022] | 22 | 223 | |
| Kamikaze | 23 | 212 | |
| GAY 4 ME [Ft. Lauren Sanderson] | 24 | 210 | |
| I Don't Wanna Do Nothing Forever | 25 | 209 |
For every song, we use the model to produce a prediction of vote count error:
| song | rank_predicted | vote_count | vote_count_error_pred |
|---|---|---|---|
| in the wake of your leave | 1 | 803 | -0.0933938 |
| Stars In My Eyes | 2 | 727 | -0.115812 |
| Say Nothing [Ft. MAY-A] | 3 | 653 | 0.172421 |
| Hardlight | 4 | 652 | -0.1654 |
| New Gold [Ft. Tame Impala/... | 5 | 555 | -0.0370119 |
| Sitting Up | 6 | 475 | -0.156502 |
| Camp Dog | 7 | 444 | -0.452626 |
| Girl Sports | 8 | 444 | -0.103302 |
| This Is Why | 9 | 434 | -0.296301 |
| Delilah (pull me out of this) | 10 | 432 | -0.0390645 |
| Let's Go | 11 | 426 | -0.447287 |
| B.O.T.A. (Baddest Of Them All) | 12 | 419 | -0.0521578 |
| Get Inspired | 13 | 399 | -0.488084 |
| Bad Habit | 14 | 333 | 0.0223163 |
| Backseat Of My Mind | 15 | 270 | -35659.8 |
| Glimpse of Us | 16 | 263 | 0.000728694 |
| It's Been A Long Day | 17 | 257 | -0.16067 |
| God Is A Freak | 18 | 251 | -0.0245248 |
| sTraNgeRs | 19 | 244 | -0.45165 |
| About Damn Time | 20 | 237 | -0.268104 |
| Stranger Days | 21 | 233 | 0.0580958 |
| Shooting Stars [Ft. Toro y Moi... | 22 | 223 | nan |
| Kamikaze | 23 | 212 | -0.240986 |
| GAY 4 ME [Ft. Lauren Sanderson] | 24 | 210 | -0.192271 |
| I Don't Wanna Do Nothing Forever | 25 | 209 | -0.332453 |
The predicted vote count error is then applied to each of the songs known vote_count in the prediction to produce a new, adjusted vote count. For the top 15 predicted tracks, the adjustment is applied 100%. Between 15 and 25 the adjustment is blended into the mean of whole adjustment dataset. Finally, the remaining tracks (ranks >25) adjusted by the mean of the whole adjustment dataset:
| song | rank_predicted | vote_count | vote_count_error_pred | vote_count_error_pred_blend | scaled_count |
|---|---|---|---|---|---|
| Say Nothing [Ft. MAY-A] | 3 | 653 | 0.172421 | 0.172421 | 766 |
| in the wake of your leave | 1 | 803 | -0.0933938 | -0.0933938 | 728 |
| Stars In My Eyes | 2 | 727 | -0.115812 | -0.115812 | 643 |
| Hardlight | 4 | 652 | -0.1654 | -0.1654 | 544 |
| New Gold [Ft. Tame Impala/Boot... | 5 | 555 | -0.0370119 | -0.0370119 | 534 |
| Delilah (pull me out of this) | 10 | 432 | -0.0390645 | -0.0390645 | 415 |
| Sitting Up | 6 | 475 | -0.156502 | -0.156502 | 401 |
| Girl Sports | 8 | 444 | -0.103302 | -0.103302 | 398 |
| B.O.T.A. (Baddest Of Them All) | 12 | 419 | -0.0521578 | -0.0521578 | 397 |
| Bad Habit | 14 | 333 | 0.0223163 | 0.0223163 | 340 |
| This Is Why | 9 | 434 | -0.296301 | -0.296301 | 305 |
| Glimpse of Us | 16 | 263 | 0.000728694 | 0.000728694 | 263 |
| Camp Dog | 7 | 444 | -0.452626 | -0.452626 | 243 |
| God Is A Freak | 18 | 251 | -0.0245248 | -0.0438179 | 240 |
| Backseat Of My Mind | 15 | 270 | nan | -0.12099 | 237 |
| Let's Go | 11 | 426 | -0.447287 | -0.447287 | 235 |
| Stranger Days | 21 | 233 | 0.0580958 | -0.0314472 | 226 |
| It's Been A Long Day | 17 | 257 | -0.16067 | -0.156702 | 217 |
| Get Inspired | 13 | 399 | -0.488084 | -0.488084 | 204 |
| Shooting Stars [Ft. Toro y Moi... | 22 | 223 | nan | -0.12099 | 196 |
| About Damn Time | 20 | 237 | -0.268104 | -0.209259 | 187 |
| GAY 4 ME [Ft. Lauren Sanderson] | 24 | 210 | -0.192271 | -0.135246 | 182 |
| Am I Ever Gonna See Your Face ... | 26 | 205 | nan | -0.12099 | 180 |
| Kamikaze | 23 | 212 | -0.240986 | -0.156989 | 179 |
| I Don't Wanna Do Nothing Forever | 25 | 209 | -0.332453 | -0.142137 | 179 |
| Passing Through | 27 | 200 | nan | -0.12099 | 176 |
| Turn On The Lights again.. [Ft... | 28 | 199 | -0.0333126 | -0.12099 | 175 |
| Jungle | 29 | 193 | -0.0229165 | -0.12099 | 170 |
| Leaving For London | 30 | 191 | -0.164406 | -0.12099 | 168 |
| Walkin | 31 | 182 | nan | -0.12099 | 160 |
Doing this produces a new, reordered prediction which hopefully has some of the inherent collection bias factored out. It's important to note that while this model can make predictions about vote count error, it is not perfect and the predictions should be taken with a grain of salt. The model is only as good as the data it was trained on, and factors such as changing public taste cannot be accounted for.
As of 24/01/2023, 12PM AEDT, the default view of 100 Warm Tunas will display ranks in their ML applied order. Results which have changed ranks due to the adjustment will be marked with text ✨ ML Model Applied, along with the original rank.
Example of a result where ranks have changed due to adjustment
The vote counts displayed on the prediction will continue to be the true number of votes collected.
You can opt out of ML applied ordering by using the controls overlay:
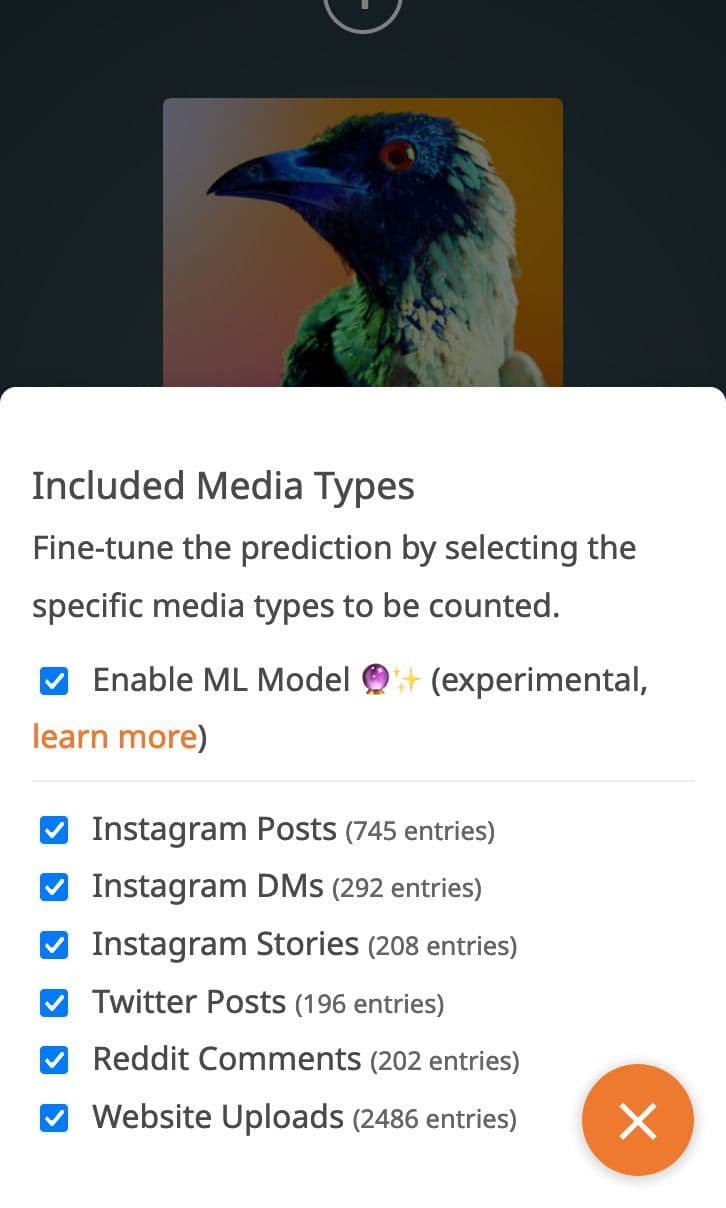
Uncheck the Enable ML Model option to opt out
We hope you enjoy these improvements to 100 Warm Tunas. If you want to show your appreciation for the work that I do, you can help contribute to the project by buying me a coffee ☕️.
Your support is greatly appreciated and helps to keep 100 Warm Tunas running for years to come.